01 它能做什么
- 跨万亿级组合化学空间做超快、模糊的药效团相似性搜索。
- 在枚举库文件(SMILES/SDF/MOL2)中做模糊相似性搜索。
- 可视化查询与命中之间映射子结构的局部相似性(match image)。
02 工作原理:特征树(Feature Tree)
FTrees 的基本原理是把分子表示成一棵叫"特征树"的树(Figure 1)。树由节点(图中彩色圆圈,代表某个分子子结构)和描述其连接关系的边组成。每个节点编码以下属性:
- 空间体积(Spatial volume)
- 环成员关系(Ring membership)
- 类药效团性质:给体、受体、酰胺样、芳香、疏水/亲水
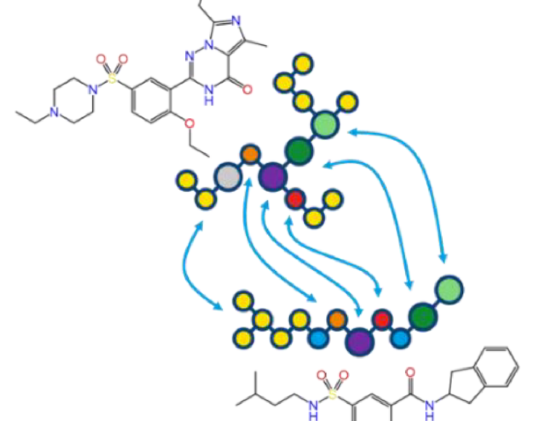
两棵树像序列比对一样相互对齐,给出两棵树上对应节点的映射。被映射的节点根据其性质轮廓比较,得到"局部相似性(Local Similarity)";"全局相似性(Global Similarity)"本质上是整体平均,用 0(不同)到 1(相同)衡量多个分子的相似程度。子结构的着色帮助识别查询的哪个子结构匹配到命中的哪个子结构。FTrees 找到的对齐(映射)是所有可能中全局相似性最高的那个。
两种算法(取决于检索对象)
- 标准分子库:查询与命中的特征树用动态规划算法对齐,使两棵树(分子)的整体相似性最大化。可输出整体相似性与局部相似性,并把对齐与局部相似性可视化——它直观展示了计算机为何认为两分子的某些部分相似或不相似。
- 化学空间导航:查询特征树被拆成片段,在遵守查询原有连接性的前提下,从化学空间里搜索相似性尽量接近目标相似性的片段;下一个片段按空间编码的连接/反应规则添加以优化相似性得分。最终从化学空间构建出一个与查询(的特征树)尽可能重叠、并最小化"目标相似性与实际相似性之差"(默认目标=完全相同)的新分子。
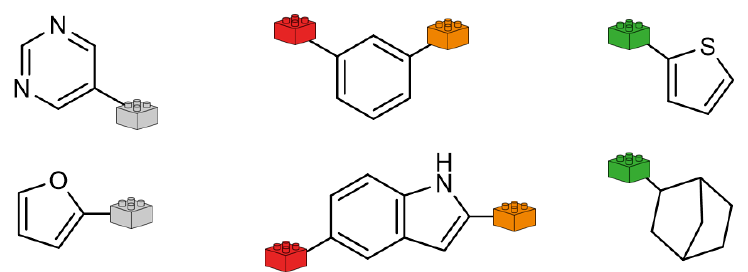
FTrees 在幕后用"乐高式"化学反应组合来遍历巨大的化学空间:把反应形式化、编码成带连接子的连接反应(Figure 2)。片段携带特定 linker(图中乐高砖),只能按反应定义所决定的、化学上有意义且可合成的方式组合——例如灰砖只能接红砖、绿砖只能接橙砖。
整体特征树相似性归一化为 0(完全不同)到 1(相同)。由于它源自编码模糊、类药效团性质的特征树节点,因此也被称为药效团相似性。正是这种模糊性,让 FTrees 能找到指纹方法会漏掉的、具有相关化学的命中(骨架跃迁)。
03 前提与授权
需要 FTrees 程序包、命令行环境与有效许可证。测试许可证直接放在 ftrees 旁。可检索的化学空间(.space 文件)从官网 Chemical Spaces 页面下载,或用 CoLibri 自建。
./ftrees --license-info
04 Jump Start:在化学空间里找骨架跃迁
最小命令——用查询去搜一个化学空间:
./ftrees -i query.sdf -s chemical_space.space
查询也可直接是 SMILES 串。默认会把 100 个最相似的命中以 SMILES 打印到控制台(STDOUT)。要写文件,用 -o(每个查询一个文件)或 -O(所有查询合并到一个文件):
./ftrees -i "CC(C)C(=O)N" -s chemical_space.space \ -o output.csv --max-nof-results 300 --min-similarity-threshold 0.8
控制台输出形如:Rank: 1 sim: 0.933 O=C(N(C(C)C)C)C WXVL021____AN0073____SB0150——依次是排名、相似性、命中 SMILES、命中名称。
05 程序选项
查询分子(.smi .smiles .mol .mol2 .sdf)或单个 SMILES 串。可多次使用 -i。
要检索的化学空间(.space)或库文件。可多次使用、可混用空间与库。
输出基名(.csv / .sdf,可同时给两者)。多查询时每个查询单独一个文件,命名为 base_{querynumber}.ext。
同上,但把所有查询结果合并写到单个文件。
为每个命中生成解释匹配的 2D 图像(.png .pdf .svg)。会显著增加运行时间,每个命中一张图。
为 SDF 输出生成 2D 坐标(增加运行时间)。
把每个命中的局部相似性值与对应子结构 SMILES 写入输出(即 match image 里那份信息的文本版)。
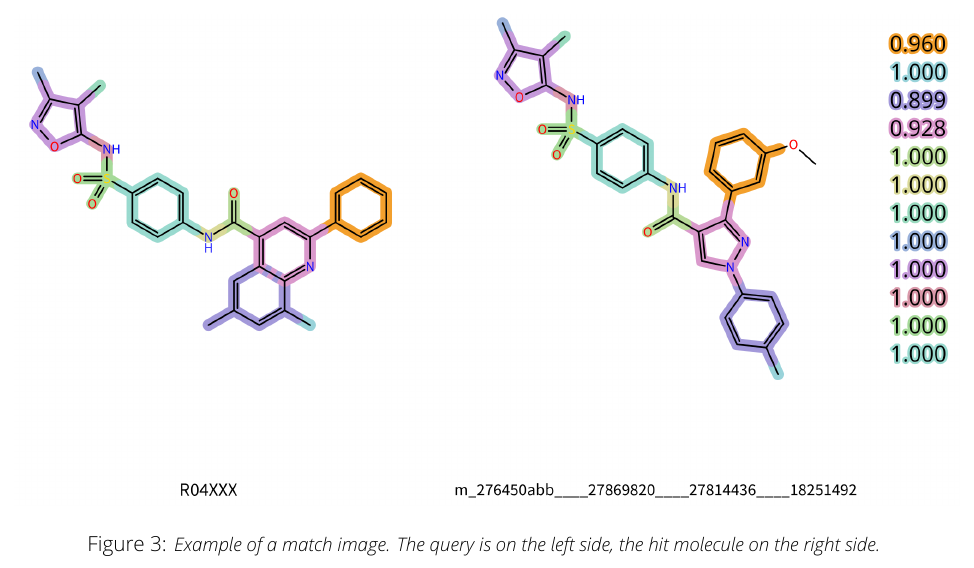
如 Figure 3:异恶唑环与苯磺酰胺部分(两分子左侧)完全相同(局部相似性 1.0);查询中央的稠合吡啶环在命中里被一个"自由"的吡唑环替代,两个苯环(紫、橙)位置相当但甲基/甲氧基取代模式不同。在 FTrees 算法语境下,这就是一次骨架跃迁。
.space 文件放在本地磁盘(与可执行文件同机)。空间文件会被缓存到本地 tmp,首次搜索后即与本地文件同速。可用 export TMPDIR=/path(Linux/Mac)或 $Env:TMP="C:\path"(Windows PowerShell)改缓存目录。
06 配置选项
| 选项 | 默认 | 说明 |
|---|---|---|
--max-nof-results | 100 | 每个查询输出的命中数(1–1,000,000),按相似性降序。 |
--min-similarity-threshold | 0.8 | 低于此相似性(0–1)的结果被丢弃。只要高度相似就设到 0.95 等。 |
--target-similarity | 1 | 期望与查询的目标相似性(0.5–1,须 ≥ 阈值)。要更接近查询设 ≥0.95;要强制明显骨架跃迁设 0.75–0.9。最接近目标值的结果排在最前。 |
--total-diversity | 1 | 结果集中任意两化合物的最大允许相似性(0.9–1)。越小越多样。仅当结果数 ≤ 500 时可用。低于 1.0 会大幅延长运行时间。 |
--expand-alternative-results | — | 展开同一命中分子的其他反应路径/重复匹配(相同排名与相似性,不同试剂/名称)。 |
07 输出文件里有什么
输出(CSV/SDF)为每个命中提供:结果排名、药效团相似性(特征树相似性)、命中名称、查询名称与 SMILES、被检索空间名,以及(仅空间搜索)构成该命中的反应名称与各试剂(reagent)的名称和 SMILES。这意味着你不仅得到命中分子,还得到它"怎么合成出来"的配方。